
 German
German Greek
Greek Spanish
Spanish Filipino
Filipino French
French Italian
Italian Dutch
Dutch Polish
Polish Portuguese (Brazil)
Portuguese (Brazil) Russian
Russian Vietnamese
Vietnamese Turkish
Turkish Ukrainian
Ukrainian Chinese (Simplified)
Chinese (Simplified) Korean
Korean Japanese
Japanese Thai
Thai Arabic
Arabic Persian
Persian July 30, 2023 6:32 pm
July 30, 2023 6:32 pm
What is GroveDB?
GroveDB is the first production-level implementation of a key-value hierarchical authenticated data structure (HADS) designed to supplement the RocksDB database of Dash Platform. Dash Core Group (DCG) created GroveDB since no existing solution provided the desired functionality for the Dash Platform. Overall, GroveDB provides three critical capabilities:
- Comprehensive querying abilities.
- Trustless queries so users know their data is accurate via cryptographic proofs.
- Efficient proofs in terms of both size and time.
Why Was GroveDB Needed?
Dash Platform is on the brink of release and will be Dash’s gateway into Web3. However, why should decentralization remain localized to the platform itself and not the overall experience? Consider this: when a user queries a database, they are essentially asking the host servers to:
- Look into their stored database.
- Return the piece of information that was requested.
The obvious problem is that you must trust the host to send you back the correct information and act ethically with your data. This is especially relevant for distributed systems like blockchains, where anyone can anonymously host the database.
A solid solution here is to use cryptographic proofs. The data receiver can verify cryptographic proofs sent by the host to ensure the validity of the data. Without cryptographic proof, the receiver can never be assured of the quality and validity of the data received.
While there are databases that utilize cryptographic proofs, they are inefficient. GroveDB stands out from the competition because of the following:
- Complex query proofs
- Immutable and mutable storage
- Non-inclusion and inclusion proofs
- ACID compliance:
GroveDB Tree Architecture
Grove (noun): A small group of trees
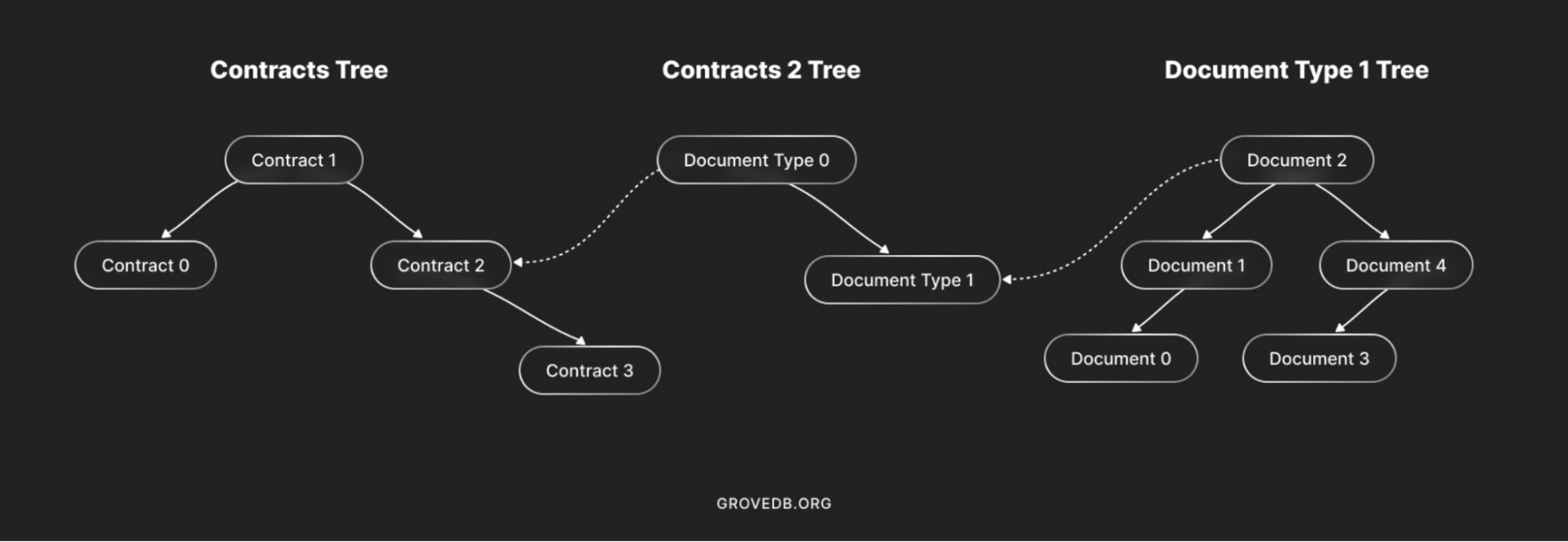
Unlike a traditional tree architecture, GroveDB uses a hierarchical, authenticated data structure based on Database Outsourcing with Hierarchical Authenticated Data Structures (HADS). The overall graph takes a form where the root hashes of lower-level trees are stored in nodes of higher-level trees, and the root hash of the root tree can be used to prove the state of the entire database. In layman’s terms, instead of using a simple Merkle tree, GroveDB takes on the form of a group (or a grove) of Merkle trees. In the current GroveDB implementation, the top-level “Root tree” has 5 subtrees – identities, contract documents, public key hashes to identities, spent asset lock transactions, and pools.
Secondary Indexes For Complex Queries
Before we get into secondary indexes, let’s understand how unique identifiers work in traditional databases. All documents or records that are stored in databases require a unique value or “identifier” to differentiate them from others. The unique identifier can be a column or field in your database – think of serial numbers in a list.
However, what if the records must be queried based on some other index, as is often true in the real world? Applications often need to query their data based on secondary fields like name, date, city, etc. Databases with secondary indexes allow users to perform complex querying operations using different data fields.
Databases that provide cryptographic proofs often struggle with handling secondary indexes due to the degree of complexity involved. With GroveDB, the engineers at Dash Core Group have achieved a crucial breakthrough with secondary index management. If you want to know more about how secondary indexing works in GroveDB, read this.
GroveDB Utility
GroveDB provides cryptographic proofs, which ensures the accuracy of the data retrieved. This functionality is invaluable when dealing with sensitive data. As such, GroveDB sees immense utility in industries where trustlessness is crucial.
As mentioned, enhanced security and advanced query capabilities will give developers a significant advantage when they deploy their dApps on Dash Platform. However, it is not necessary to deploy your applications on Dash Platform to leverage the functionality of GroveDB.
GroveDB has been designed to be a standalone product that can be integrated with any system using RocksDB. An example of integration using Rust can be seen in rs-drive. GroveDB also has bindings for Node.js to support JavaScript developers.
How Do I Get Started With GroveDB?
Here, we will give you a brief overview of how you can start working with GroveDB. You will find a detailed tutorial here.
The first thing you need to do is clone the GroveDB repository. Now, let’s run our tutorials. First up, you will need to build the tutorial code:
cd grovedb/tutorials
cargo build
Execute the tutorials using this:
cargo run --bin ❮tutorial name❯
The <tutorial name> will have the tutorials that you can run:
- open
- insert
- delete
- query-simple
- query-complex
- proofs
Tutorial #1: open
- The open() function opens an existing instance of GroveDB at the given path
- If no existing file exists, a new one will be created with an empty root tree.
Tutorial #2: insert
- The insert() function allows GroveDB to insert items into storage.
- By default, inserting overwrites values unless the value is a tree.
Tutorial #3: delete
- The delete() function deletes key-values from storage.
Tutorial #4: Queries (query-simple and query-complex)
- The query() function allows GroveDB to perform queries on storage.
- Query functions can either be simple or complex.
- When you execute a simple query, GroveDB retrieves the subset of the requested item and prints the result in the terminal.
- A complex query allows you to send two subqueries along with the main query. No more than 10 items may be displayed in the result.
Tutorial #5: proofs
- The prove_query() function generates query proofs by taking a path query as an argument.
- The verify_query() function to verifies query proofs. By taking a path query and proof.
Are You Ready To Use GroveDB?
As a developer, it is clear to see the advantages of using a database like GroveDB. Currently, it is the only efficient implementation of a cryptographic proof-based database that supports complex queries. We recommend that you go through our GroveDB tutorials to get up to speed on the basics.
When you’re ready to start building, head to the crate homepage for instructions on adding GroveDB to your project and links to the docs.
Author: Anon
About the author

Paul DeLucia
Researcher and Rust Developer