You are using an out of date browser. It may not display this or other websites correctly.
You should upgrade or use an alternative browser.
You should upgrade or use an alternative browser.
Dash Core v19.0.0 Release Announcement
- Thread starter Pasta
- Start date
Yeah, somewhere around 3 days from now is when we will see what miners have upgraded so far. I recommend looking at https://www.dashninja.pl/blocks.html. Once miners start signaling there will be a second Block Version that shows up in the "Per Version Statistics (last 24h)" section. The owner of the site you listed has been notified and will hopefully update to track v19 adoption soon, but they're not associated with DCG so we'll just have to see.So where (and possibly also when) can we follow miners adoption of v19 exactly ?
This site still only shows miners adoption of v18 : http://178.254.23.111/~pub/Dash/Dash_Info.html
Has v19 hard fork signaling not already started for miners by now ? Or are we waiting for masternodes support (80%) first ?
I seem to recall something has changed recently on how this all works these days (hard fork / spork / enhanced hard fork implementation / mined masternode majority support signal / special message in a block).
If you're running Core, you can check using the getblockchaininfo command and look under bip9_softforks -> v19. After the signaling window starts you'll be able to see statistics there.
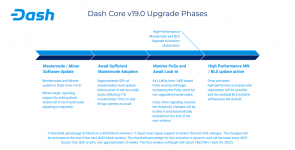
Also, the attached image shows basically how things move along. The enhanced hard fork DIP isn't fully implemented yet so we're still following the same activation process as the previous 2 releases (diminishing miner threshold over time).
Attachments
qwizzie
Well-known member
Yeah, somewhere around 3 days from now is when we will see what miners have upgraded so far. I recommend looking at https://www.dashninja.pl/blocks.html. Once miners start signaling there will be a second Block Version that shows up in the "Per Version Statistics (last 24h)" section. The owner of the site you listed has been notified and will hopefully update to track v19 adoption soon, but they're not associated with DCG so we'll just have to see.
If you're running Core, you can check using the getblockchaininfo command and look under bip9_softforks -> v19. After the signaling window starts you'll be able to see statistics there.
Also, the attached image shows basically how things move along. The enhanced hard fork DIP isn't fully implemented yet so we're still following the same activation process as the previous 2 releases (diminishing miner threshold over time).
Thank you for that reply.
I have another question that is unrelated to the above (although it may get influenced by v19 at some point).
One of my masternodes (v19) recently got PoSe scored with a fairly high PoSe score and was already getting lower in PoSe score by the time i noticed it due to -1 score per block.
I checked my debug.log and found the protx hash of my masternode and a reference to the PoSe score (only one-time printed in my debug.log). But instead of seeing just my own masternode getting PoSe scored there, i saw a number of other masternodes (6 or 8 ? not sure) getting PoSe scored at the same time as well (with the same high PoSe score, i think). I assume at this point that these high PoSe scores relate to those masternodes failing to participate in a DKG session. When a masternode fails to participate in a DKG session, it gets PoSe scored with a rather high number (66% of total number of masternodes).
Does the network know a specific masternode is at fault during failure to participate in a DKG session and PoSe score just that one masternode, or does the network PoSe score all selected masternodes in one specific quorum, if one of them fail to participate in a DKG session ?
That could explain why i saw a number of other masternodes getting PoSe scored pretty much at the same time and with (if i remember correctly) the same PoSe score. Or are those other masternodes i saw in my debug.log getting PoSe scored from failing to participate in a DKG session from other quorums ?
And is there something in v19 that either now or after activation makes getting PoSe scored for masternodes / HPMN's also less an issue ?
I seem to recall v19 fixed something (an old lingering issue) with regards to PoSe scoring masternodes, but i can't remember what exactly.
Last edited:
I checked my debug.log and found the protx hash of my masternode and a reference to the PoSe score (only one-time printed in my debug.log). But instead of seeing just my own masternode getting PoSe scored there, i saw a number of other masternodes (6 or 8 ? not sure) getting PoSe scored at the same time as well (with the same high PoSe score, i think). I assume at this point that these high PoSe scores relate to those masternodes failing to participate in a DKG session. When a masternode fails to participate in a DKG session, it gets PoSe scored with a rather high number (66% of total number of masternodes).
I see the same thing all the time, this seems to be normal.
Does the network know a specific masternode is at fault during failure to participate in a DKG session and PoSe score just that one masternode, or does the network PoSe score all selected masternodes in one specific quorum, if one of them fail to participate in a DKG session ?
Yes, it is supposed to be scoring just the few that failed to show up for roll call, if it were mistakenly scoring all the nodes in the quorum, it would be much higher.
There are several factors that can lead to scoring.
- Bugs in the core node code, we've seen a lot of those in v18 and v19 and tried to fix them all, others may still exist.
- The node is actually off-line.
- The network our VPS is on is off-line.
- Routing issues on the internet.
- The node you are talking to has for some reason 'discouraged' your node ie, it no longer listens to you and thus misses your reply and THEN scores you! We see a LOT of this on testnet.
- Some VPS providers purposely firewall certain networks, I know that coins.host for example F/W traffic between other VPS's on their own network!
- Your node is online, but not at the current tip.
- Your node is online, but severely resource constrained, eg CPU and is SLOW to respond. This can be a fleeting occurrence, since the load on dashd is not constant and if you are using a shared instance it could even be because someone else's VPS is suddenly super busy and drains CPU resources from your own instance !
- Your protx is revoked - Obvious and easy to remedy.
- Your collateral is spent, instant ban.
- You are running a software F/W on your VPS that is interfering or has a rate limit.
- VPS is doing a reboot.
- Malicious nodes? Note that to score a node, it must be voted by others in the quorum too, how many exactly, I don't know. Large operators are incentivised to attack smaller operators, this should be obvious.
- The rogue node, a node that thinks it is synced to tip and erroneously votes to score others that are actually properly synced up.
- etc etc etc.
Last edited:
qwizzie
Well-known member
Thank you for that detailed list of factors, that can lead to PoSe scoring on masternodes.
That would mean that at a very specific point in time the network PoSE scored misbehaving masternodes who were selected in different quorums (6 or 8) at the same time, all involved in a DKG session. Sounds to me like the network had trouble forming a successfull quorum / DKG session at that specific time and had to try a number of times before it finally succeeded.
Also was there not a fix that would limit masternodes getting selected to different quorums at the same time ? I just remembered something like that. That would mean its not the same masternodes in those different quorums (just thinking outloud here, not forming a conclusion).
Personally i have the most difficulty with having no specific reason provided in the debug.log why my masternode was PoSe scored in the first place. Instead i will just need to take into account a whole list of possible factors of why my masternode is getting PoSe scored.
This makes the PoSe scoring system for both masternodes and HPMN's, not very clear to MNO's.
It would be helpfull if we could get some additional info in our debug.log about the PoSe score, for each PoSe scored masternode.
Yes, it is supposed to be scoring just the few that failed to show up for roll call, if it were mistakenly scoring all the nodes in the quorum, it would be much higher.
That would mean that at a very specific point in time the network PoSE scored misbehaving masternodes who were selected in different quorums (6 or 8) at the same time, all involved in a DKG session. Sounds to me like the network had trouble forming a successfull quorum / DKG session at that specific time and had to try a number of times before it finally succeeded.
Also was there not a fix that would limit masternodes getting selected to different quorums at the same time ? I just remembered something like that. That would mean its not the same masternodes in those different quorums (just thinking outloud here, not forming a conclusion).
Personally i have the most difficulty with having no specific reason provided in the debug.log why my masternode was PoSe scored in the first place. Instead i will just need to take into account a whole list of possible factors of why my masternode is getting PoSe scored.
This makes the PoSe scoring system for both masternodes and HPMN's, not very clear to MNO's.
It would be helpfull if we could get some additional info in our debug.log about the PoSe score, for each PoSe scored masternode.
Last edited:
Yes. this was a main feature of Quorum Rotations introduced in vers 18. Ody is the expert in this area, I will refer him to this thread.Also was there not a fix that would limit masternodes getting selected to different quorums at the same time ? I just remembered something like that. That would mean its not the same masternodes in those different quorums (just thinking outloud here, not forming a conclusion).
qwizzie
Well-known member
Example of Pose scoring found in a recent debug.log (no idea who's masternodes these are):
If we focus purely on masternodes that get PoSe punished for failing to participate in a DKG session for the first time, the following three masternodes (in what i assume at this point are three different quorums) get PoSe punished all at the same time :
I noticed in my debug.log what i discussed in my previous posts (and no longer have) a few more masternodes (6 or 8 ?) getting PoSe punished all at the same time, for failing to participate in a DKG session for the first time (0-> ....).
Is this simply a case of masternodes failing to participate in a DKG session through three separate quorums, all at the same time ?
Or looking at my older debug.log that i am describing from memory : is that simply a case of masternodes failing to participate in a DKG session through a lot more then three separate quorums, all at the same time ?
The higher i see the number of masternodes getting PoSe punished for failing to participate in a DKG session for the first time (0->2917) and all getting PoSe punished at the very same time, the more i wonder if this is perhaps some kind of lingering PoSe scoring bug.
2023-04-27T12:29:31Z [ProcessBlock] h[1861386] numCommitmentsRequired[32] numCommitmentsInNewBlock[32]
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN d682be4c0a1e5ef524d6710ea23b44a6b71ceab4dd593500f5c9d0a7810d0472, penalty 2629->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: poSePunish -- banned MN d682be4c0a1e5ef524d6710ea23b44a6b71ceab4dd593500f5c9d0a7810d0472 at height 1861386
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN b47e7267d411d39f066ca29b15ead6a3abd3cfe2f7ff65b51258bbf4b561186b, penalty 2526->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- banned MN b47e7267d411d39f066ca29b15ead6a3abd3cfe2f7ff65b51258bbf4b561186b at height 1861386
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 3e105f917023523c82bc63a9437b621bcae0ef64ad2ea01627906a04c41b840b, penalty 2629->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- banned MN 3e105f917023523c82bc63a9437b621bcae0ef64ad2ea01627906a04c41b840b at height 1861386
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 8e42c90f1f1b92776bed34fd24cacfa69f329666a135e2d40dce57f11523dd8c, penalty 4421->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 9fe424cf9269d647ecb4a65e191253f9fc44eed3ea1409c744b962d5ebc17efd, penalty 4421->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN c09b7d1ff2691eaa68429746f7dc0bc69f9532f8a5e9f9b0a2bfce51c9d777c5, penalty 2629->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- banned MN c09b7d1ff2691eaa68429746f7dc0bc69f9532f8a5e9f9b0a2bfce51c9d777c5 at height 1861386
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 5cdfcfd741502e7230df5c1d4dca352d3dad4111bc2e91548ee361bb1ad3754e, penalty 0->2917 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 3b79a6250d676a83d6cfc2d5c288aec10ed47f149c25f844c3bc0c7aa32882e8, penalty 4421->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN cb605526498d78a3b16d9907cd8de83d832b12ba86dfcf99052dd38ed5e57f9d, penalty 2629->4421 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- banned MN cb605526498d78a3b16d9907cd8de83d832b12ba86dfcf99052dd38ed5e57f9d at height 1861386
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 1948f3beda90d4aac1ab6bff3c04bf83d5a3862ea7dafc3403152fba90742d83, penalty 0->2917 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 200a4c237150cb06a3e55af689bdf13cc1f2be2fe5873b0a62b9b970fa4f6996, penalty 0->2917 (max=4421)
2023-04-27T12:29:32Z UpdateTip: new best=000000000000001ee75542c6596e6dc22aafe3271a9a84de6d7b015b99f06112 height=1861386 version=0x20000000 log2_work=79.036706 tx=47414274 date='2023-04-27T12:29:00Z' progress=1.000000 cache=2.2MiB(16680txo) evodb_cache=1.6MiB
If we focus purely on masternodes that get PoSe punished for failing to participate in a DKG session for the first time, the following three masternodes (in what i assume at this point are three different quorums) get PoSe punished all at the same time :
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 5cdfcfd741502e7230df5c1d4dca352d3dad4111bc2e91548ee361bb1ad3754e, penalty 0->2917 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 1948f3beda90d4aac1ab6bff3c04bf83d5a3862ea7dafc3403152fba90742d83, penalty 0->2917 (max=4421)
2023-04-27T12:29:32Z CDeterministicMNList: PoSePunish -- punished MN 200a4c237150cb06a3e55af689bdf13cc1f2be2fe5873b0a62b9b970fa4f6996, penalty 0->2917 (max=4421)
I noticed in my debug.log what i discussed in my previous posts (and no longer have) a few more masternodes (6 or 8 ?) getting PoSe punished all at the same time, for failing to participate in a DKG session for the first time (0-> ....).
Is this simply a case of masternodes failing to participate in a DKG session through three separate quorums, all at the same time ?
Or looking at my older debug.log that i am describing from memory : is that simply a case of masternodes failing to participate in a DKG session through a lot more then three separate quorums, all at the same time ?
The higher i see the number of masternodes getting PoSe punished for failing to participate in a DKG session for the first time (0->2917) and all getting PoSe punished at the very same time, the more i wonder if this is perhaps some kind of lingering PoSe scoring bug.
Last edited:
As xkcd mentioned, it only scores the nodes that were determined to not be participating correctly (by consensus during DKG). There is a minimum number of MNs required to form each quorum type, so there is a floor to how many MNs could be scored in a particular session. For example, the quorum used by InstantSend has a minimum size of 50 members (it's full size is 60). So, if during DKG there are more than 10 "bad" MNs, that DKG session will fail to form a quorum. Therefore, you could never have a DKG session for that quorum type that PoSe scored/banned more than 10 MNs.
Quorum rotation does limit MNs from being put in multiple quorum simultaneously, but it is only used for the InstantSend quorums which are the most heavily used ones. So the MN could be in an IS quorum plus one or more of the other quorum types.
Also, an important note here is that the InstantSend quorums are forming basically in parallel so you have 32 quorums * 60 members/quorum all doing DKG. So to put it in perspective, assuming a 98% success rate (randomly chosen) when forming IS quorums, 40 MNs could be scored in a small span of blocks (since there's nearly 2000 MNs doing DKGs).
Generally speaking, it's not really possible to know the specific reason. The MNs marking you as "bad" only really know that either: 1. they didn't receive your contribution or 2. you sent a bad contribution. I would expect the reason is almost never #2. Your MN knows whether or not it tried to participate but doesn't know if its contribution was relayed around IIRC (DKG is very message intensive as it is so I don't think there is handshaking/feedback on every step).
Quorum formation doesn't really have a retry process. If DKG fails to create a quorum, nothing happens until the next time DKG is due (24, 288, or 576 blocks later depending on quorum type).That would mean that at a very specific point in time the network PoSE scored misbehaving masternodes who were selected in different quorums (6 or 8) at the same time, all involved in a DKG session. Sounds to me like the network had trouble forming a successfull quorum / DKG session at that specific time and had to try a number of times before it finally succeeded.
Also was there not a fix that would limit masternodes getting selected to different quorums at the same time ? I just remembered something like that. That would mean its not the same masternodes in those different quorums (just thinking outloud here, not forming a conclusion).
Quorum rotation does limit MNs from being put in multiple quorum simultaneously, but it is only used for the InstantSend quorums which are the most heavily used ones. So the MN could be in an IS quorum plus one or more of the other quorum types.
Also, an important note here is that the InstantSend quorums are forming basically in parallel so you have 32 quorums * 60 members/quorum all doing DKG. So to put it in perspective, assuming a 98% success rate (randomly chosen) when forming IS quorums, 40 MNs could be scored in a small span of blocks (since there's nearly 2000 MNs doing DKGs).
There are additional logs that can be enabled for debugging, but they're very verbose and hard (for me anyway) to parse.Personally i have the most difficulty with having no specific reason provided in the debug.log why my masternode was PoSe scored in the first place. Instead i will just need to take into account a whole list of possible factors of why my masternode is getting PoSe scored.
This makes the PoSe scoring system for both masternodes and HPMN's, not very clear to MNO's.
It would be helpfull if we could get some additional info in our debug.log about the PoSe score, for each PoSe scored masternode.
Generally speaking, it's not really possible to know the specific reason. The MNs marking you as "bad" only really know that either: 1. they didn't receive your contribution or 2. you sent a bad contribution. I would expect the reason is almost never #2. Your MN knows whether or not it tried to participate but doesn't know if its contribution was relayed around IIRC (DKG is very message intensive as it is so I don't think there is handshaking/feedback on every step).
qwizzie
Well-known member
If masternodes continue to be slow at updating from this point on and endanger the next possible activation time window (20th of May, 2023), DCG could consider creating a budget proposal for 0 dash, to inform masternodes to update to v19 ASAP.
It will be a way of reaching out to masternode owners directly, through the Dash Budget System.
It will be a way of reaching out to masternode owners directly, through the Dash Budget System.
Masternodes don't really put the activation at risk. Based on miner signaling, the network _will_ hard fork once the activation is locked in. Masternodes not upgraded by that time will stop following the chain that the miners are creating and be forked off.If masternodes continue to be slow at updating from this point on and endanger the next possible activation time window (20th of May, 2023), DCG could consider creating a budget proposal for 0 dash, to inform masternodes to update to v19 ASAP.
It will be a way of reaching out to masternode owners directly, through the Dash Budget System.
Of course, it would not be ideal for the network to lose such a large number of masternodes all at once and I very much hope to see the adoption rate pick up soon.

vazaki3
Well-known member
Who decided that 80% of the masternodes must upgrade to v19, in order to start a fork?
Why not 75% or 89% ? Lets vote the numbers about this 80% !!!!
Tools for the "votethenumbers" technology.
(under construction)
STUPID SLAVES OF THE "gOD" WHO DECIDED THIS 80%, WAKE UP!!!!!!!
Why not 75% or 89% ? Lets vote the numbers about this 80% !!!!
Tools for the "votethenumbers" technology.
STUPID SLAVES OF THE "gOD" WHO DECIDED THIS 80%, WAKE UP!!!!!!!
Last edited:
vazaki3
Well-known member
Who decided that 80% of the masternodes must upgrade to v19, in order to start a fork?
Why not 75% or 89% ? Lets vote the numbers about this 80% !!!!
Tools for the "votethenumbers" technology.
(under construction)
STUPID SLAVES OF THE "gOD" WHO DECIDED THIS 80%, WAKE UP!!!!!!!
The issue is primarily the reason why all this is happening.
Is there any reason for this number to be as it is? Is there any reason for this number to be stable, or dynamic? Is there any reason for this number to be decided by some maths rather than by a vote? And is there any reason for this number(or method) to apply equally to all the software versions that are about to cause a fork ??? (obviously not all versions are of equal importance, thus an equal percentage should not apply to all versions) .... If there is a reason, I would like to hear it.
So does anyone knows...?
1)The reason
2) The math
If anyone knows, let us also know about it.
If no one knows, at least do we know the "gOD" who decided this stupid 80% percentage?
Where is your "gOD"?
Last edited:
qwizzie
Well-known member
I thought a spork was needed to be flipped manually by DCG to complete the update / hard fork. A spork depending on masternodes reaching 80% first. If that is not the case and only miners are required to signal readyness to v19 to a certain percentage, then that is only better for the update process. In the mean time i will take a closer look at the v19 upgrade phase that is mentioned in the last Dash Platform & Core Development Update (i had diifficulty reading it on Youtube and could not find it in de Dash Core v19 Product Brief).Masternodes don't really put the activation at risk. Based on miner signaling, the network _will_ hard fork once the activation is locked in. Masternodes not upgraded by that time will stop following the chain that the miners are creating and be forked off.
Of course, it would not be ideal for the network to lose such a large number of masternodes all at once and I very much hope to see the adoption rate pick up soon.
Update : Looks like that 80% of masternodes needed to update to v19 is in order to effectively start the PoSe scoring process on v18 masternodes, nothing to do with flipping on a possible new spork.
Last edited:
vazaki3
Well-known member
I thought a spork was needed to be flipped manually by DCG to complete the update / hard fork. A spork depending on masternodes reaching 80% first. If that is not the case and only miners are required to signal readyness to v19 to a certain percentage, then that is only better for the update process. In the mean time i will take a closer look at the v19 upgrade phase that is mentioned in the last Dash Platform & Core Development Update (i had diifficulty reading it on Youtube and could not find it in de Dash Core v19 Product Brief).
Looks like that 80% of masternodes needed to update to v19 is in order to effectively start the PoSe scoring process on v18 masternodes, nothing to do with flipping a possible new spork.
The miners decide the fork? WHO THE HELL DECIDED THAT RULE????????????????????????????????
So could the miners decide, for example, a malicious fork that will rob all the money from the masternodes and cease their voting rights?
ARE YOU NUTS?????
AND WHAT THE HELL DOES @amanda_b_johnson SAYS IN THE ABOVE OFFICIAL DASH VIDEO?
SHE SAYS THAT THE MASTERNODES DECIDE!
IS SHE LYING?
Last edited:
qwizzie
Well-known member
I do wonder if this mean there is no more flipping things on (spork-wise) for Dash Core Group, before launch and activation of Dash Platform on Dash Mainnet. Or does Dash Core v20 require some manual flipping things on (spork-wise) from DCG ?
Also with the SEC considering Dash a security and most likely having a pretty good idea who DCG consist of exactly, it is perhaps better to phase this centralized aspect of the Dash spork process out rather sooner then later.
Also with the SEC considering Dash a security and most likely having a pretty good idea who DCG consist of exactly, it is perhaps better to phase this centralized aspect of the Dash spork process out rather sooner then later.
Last edited:
There is a spork related to PoSe, but for this release it was not changed. So no action is needed by DCG. Masternodes just need to upgrade to get PoSe rolling. The 80% is simply the point at which DKG sessions are able to form in a way that enables PoSe to begin working really well (I believe it is slightly effective a bit lower than that per @Pasta). I attached the file I think you were looking for.I thought a spork was needed to be flipped manually by DCG to complete the update / hard fork. A spork depending on masternodes reaching 80% first. If that is not the case and only miners are required to signal readyness to v19 to a certain percentage, then that is only better for the update process. In the mean time i will take a closer look at the v19 upgrade phase that is mentioned in the last Dash Platform & Core Development Update (i had diifficulty reading it on Youtube and could not find it in de Dash Core v19 Product Brief).
Update : Looks like that 80% of masternodes needed to update to v19 is in order to effectively start the PoSe scoring process on v18 masternodes, nothing to do with flipping on a possible new spork.
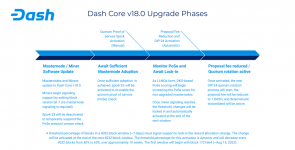
As far as miners determining the fork, this is how every planned Dash hard fork works (at least all that I'm aware of in the last 6 yrs). We use the BIP9 mechanism that Bitcoin does (slightly modified to reduce the threshold from 80% -> 60% over time if activation doesn't occur). That being said, full implementation of Pasta's enhanced hard fork logic (DIP23) is targeted for v20. That will make it a joint effort requiring masternodes to signal also prior to a fork occurring.
Also, I'm not certain about v20 / Platform, but I think Platform will simply wait to see activation on the Core chain before it "wakes up".
Attachments
vazaki3
Well-known member
We use the BIP9 mechanism that Bitcoin does (slightly modified to reduce the threshold from 80% -> 60% over time if activation doesn't occur).
dash/doc/release-notes/dash/release-notes-0.16.0.1.md at master · dashpay/dash
Dash - Reinventing Cryptocurrency. Contribute to dashpay/dash development by creating an account on GitHub.
 github.com
github.com
In Dash we have used lower thresholds (80% vs 95% in BTC) to activate upgrades via a BIP9-like mechanism for quite some time. While it's preferable to have as much of the network hashrate signal update readiness as possible, this can result in quite lengthy upgrades if one large non-upgraded entity stalls all progress. Simply lowering thresholds even further can result in network upgrades occurring too quickly and potentially introducing network instability. This version implements BIP9-like dynamic activation thresholds which drop from some initial level to a minimally acceptable one over time at an increasing rate. This provides a safe non-blocking way of activating proposals.
This mechanism applies to the Block Reward Reallocation proposal mentioned above. Its initial threshold is 80% and it will decrease to a minimum of 60% over the course of 10 periods. Each period is 4032 blocks (approximately one week).